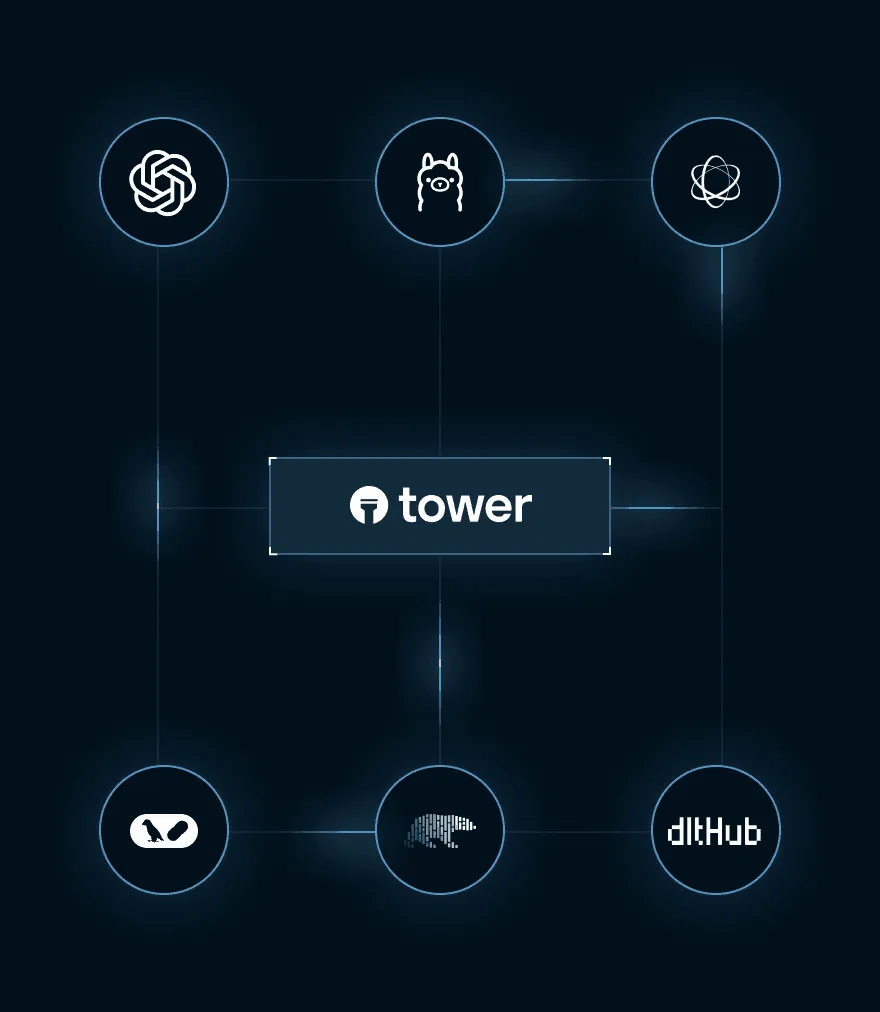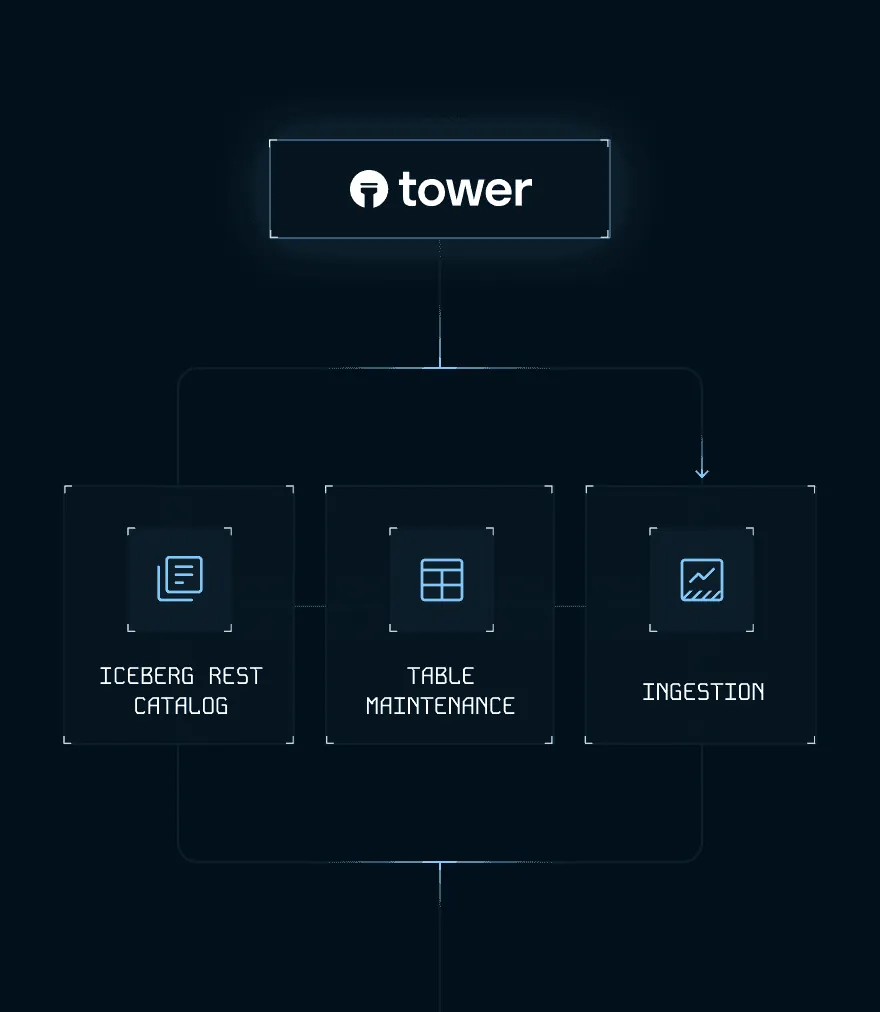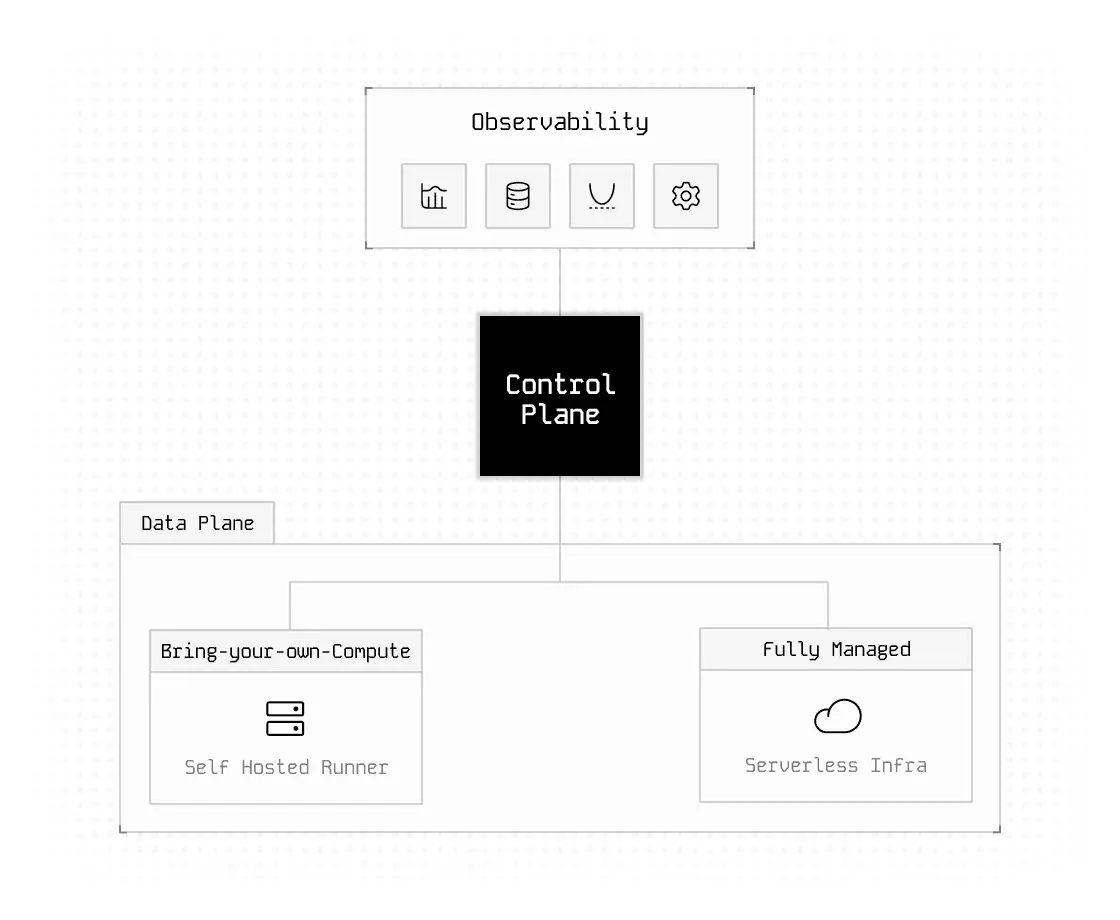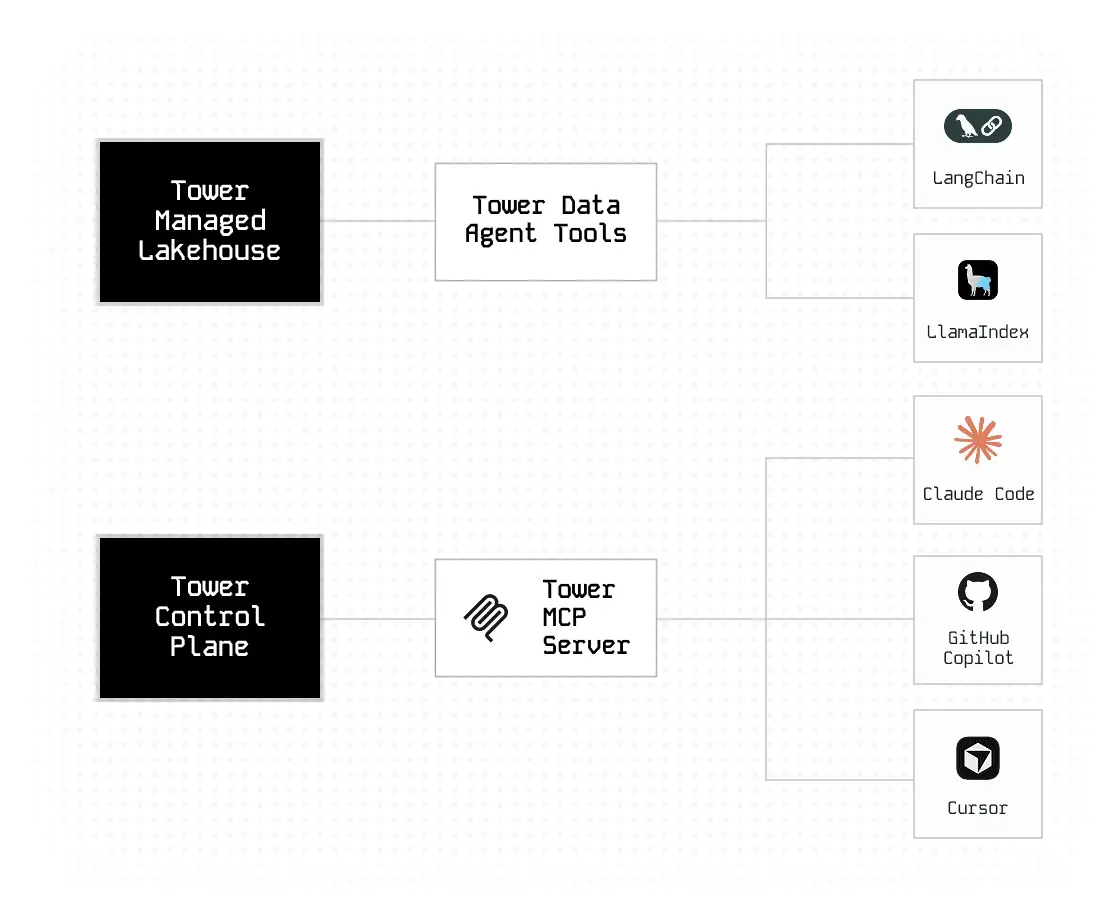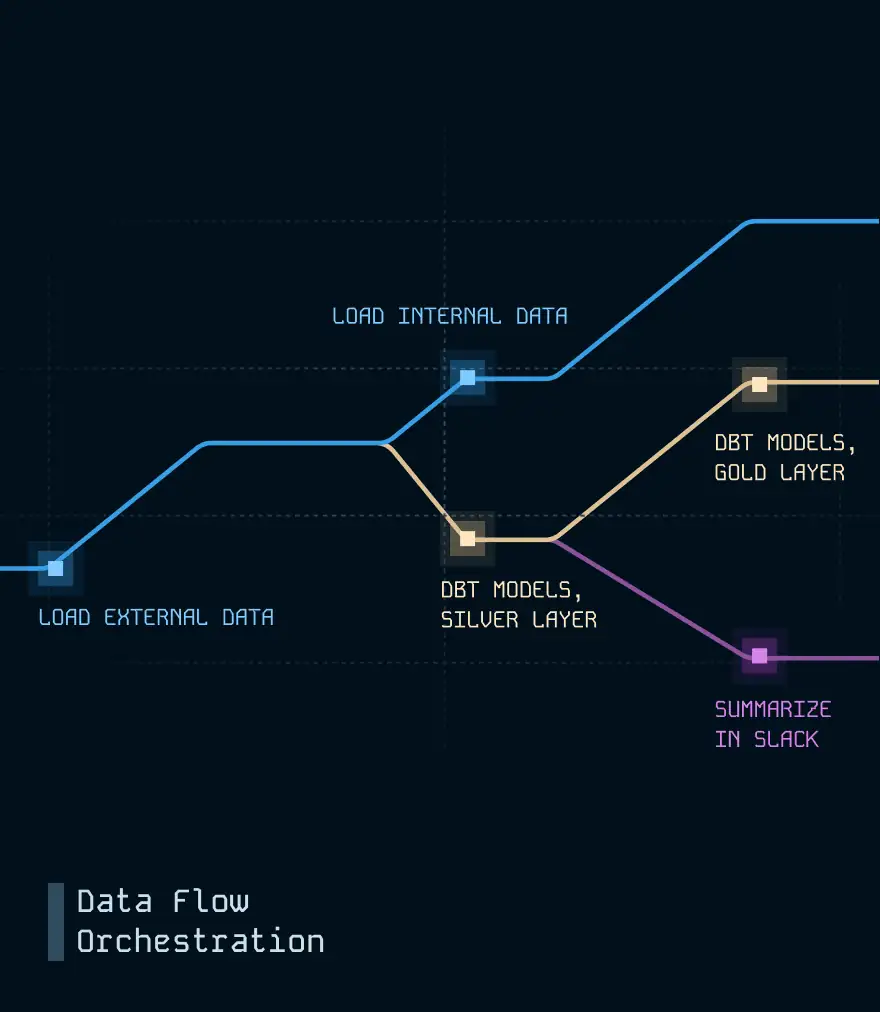
Fully-managed data flow orchestration
- Flows: Choose between Pythonic control flows and Agentic workflows
- Observability: Gain full flow observability, logs, alerts and metrics
- Configuration: Manage your settings and secrets in dedicated environments from dev to prod